I’ve now got more than thirty days of real cost data on the dashboard I built in Claude Code, the one a lot of you found through this video, which is about to cross 100,000 views. Before I tell you the number, guess.
Most people assume running something like this is expensive. AI calls, a database, hosting, audio transcription; it adds up in your head.
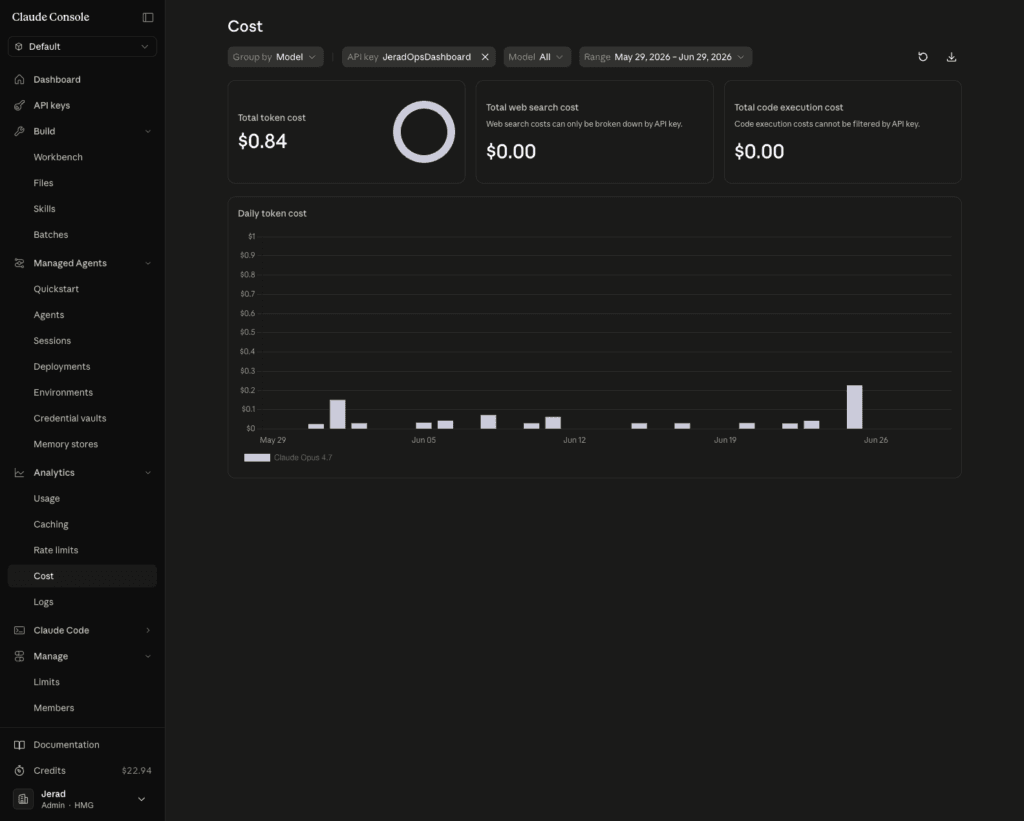
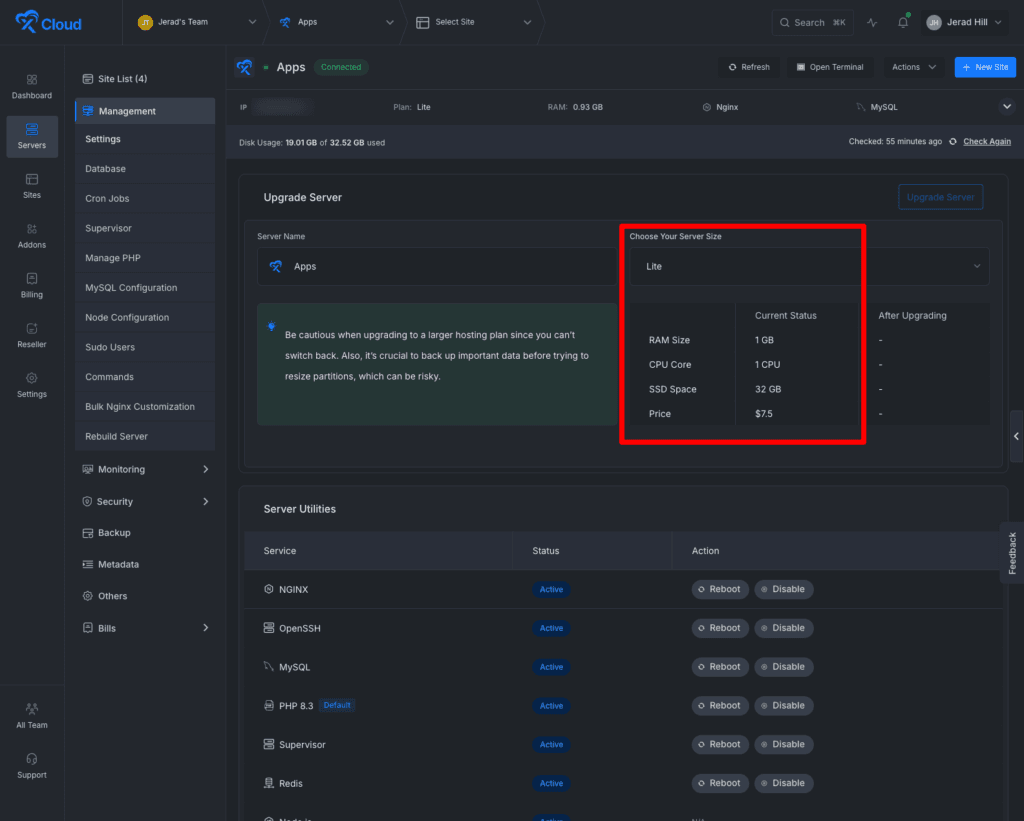
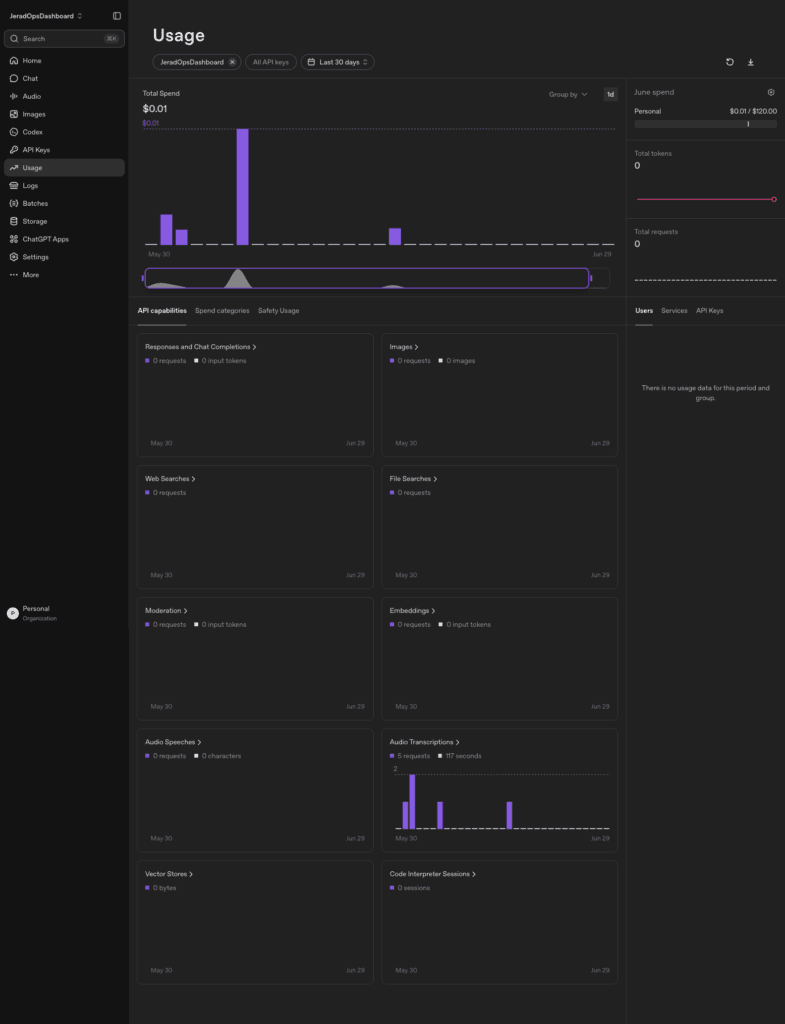
Here’s the actual monthly cost:
- OpenAI (audio transcription): less than $0.02
- Anthropic API (parsing captured items): less than $1.00
- Hosting: $7.50/month — and that’s shared with three other things I run (Umami analytics, Uptime Kuma, and an idle n8n install I haven’t touched in months)
So the system that manages my entire life, every task, project, client retainer, piece of content, note, quote, and book highlight, costs me a couple of dollars in AI and a slice of a $7.50 server.
But the number is only half the story. The more honest half is why it’s so cheap.
I’m barely using the expensive parts
Here’s the thing nobody tells you in a build video: I don’t use the AI features as much as I could.
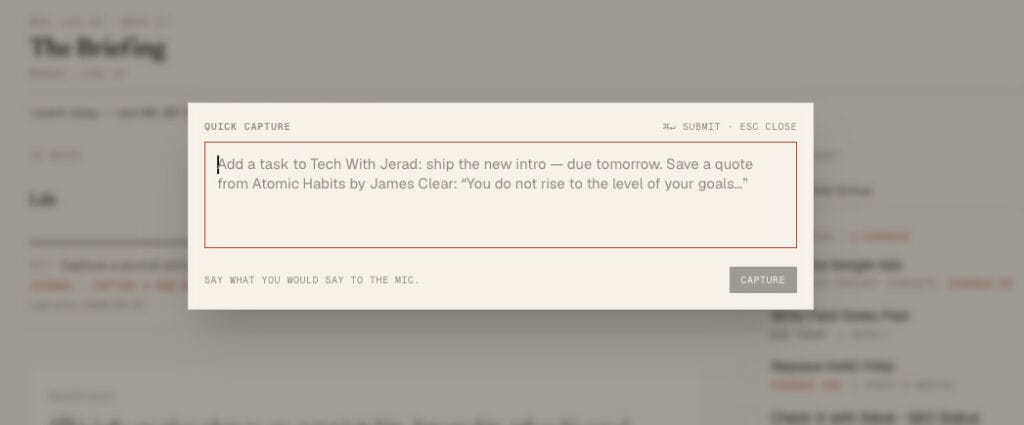
The OpenAI cost is low because I default to typing rather than speaking. I’d love to say I’m capturing everything by voice like some frictionless future, but the truth is I’m usually in bed before falling asleep, in a meeting, or in a crowded coffee shop when I go to add something, none of which are great for talking to my phone or watch. So I type.
The Anthropic cost is low because I only trigger it with the Command+J capture on desktop, and honestly, for a simple task it’s just as fast to add it manually. I reach for the AI when there’s something it genuinely handles better, setting up recurring properties, connecting a task to a project, parsing something complex. I need to force myself to use it more, because it does save time. Old habits die hard.
If I used voice capture daily the way the system is designed for, I estimate OpenAI might reach $0.50 and Anthropic maybe $5.00 a month. Still dramatically cheaper than stitching together two or three separate tools to approximate what this one does.
That’s the real headline. Not “AI is cheap.” It’s that the cost of running something you build has collapsed to almost nothing. Which means cost was never the thing standing between you and a system that works.
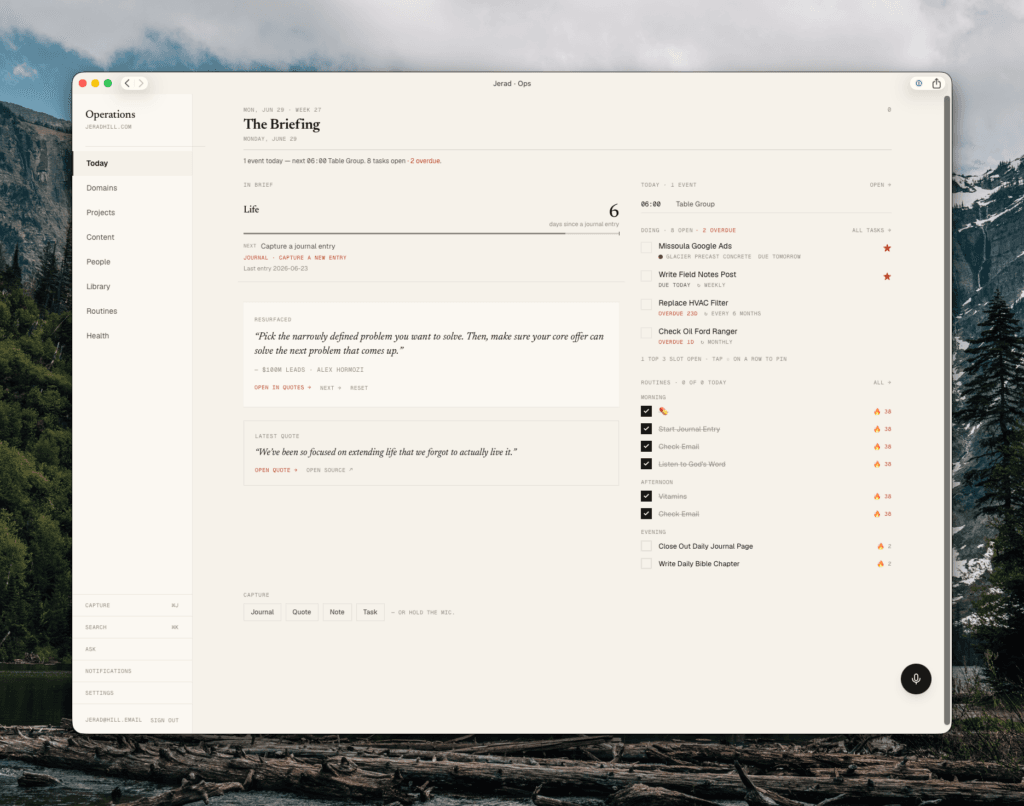
So why does everyone keep jumping ship?
If the systems are cheap and capable, why do people cycle through them endlessly?
I watch it happen all the time. Someone posts a video about how a new tool or system completely changed their life, and two weeks later there’s another video about an entirely different system that’s now the one. Build to build to build. A constant search for the thing that finally fixes it, never quite landing.
But none of us actually want to live that way. Nobody wants to keep migrating their life into a new system every quarter. We want one thing that works and that can adapt as we grow.
That’s the real problem, and it’s not a discipline failure on the user’s part. It’s an architecture failure in the tools. Most systems lock your data into a structure built for one specific purpose. The moment you outgrow that structure, when your life gets more complex, or your work shifts, or you need the pieces to connect in a new way, you can’t reshape it. So you leave. You go find the next thing. And you pour your life into a new container, knowing somewhere in the back of your mind you’ll probably outgrow this one too.
“You just rebuilt Obsidian”
One of the criticisms I got on the video was that I’d simply rebuilt Obsidian. I want to answer that honestly, because the answer is the whole point.
Obsidian is excellent. But Obsidian is a notes app with bolt-ons. It starts as text-based notes, and you add plugins to get the features you want. By the time you’ve installed a dozen plugins to make it behave like a life management system, managing the notes themselves has become the friction. The foundation was never designed to connect every area of your life; it was designed to handle notes, with everything else stapled on top.
What I built was designed from the data up. The structure exists to connect domains, projects, tasks, content, people, and reference material to each other from the start. That’s not a knock on Obsidian; it’s a different thing entirely. And it’s exactly the difference that determines whether you’ll still be using a system a year from now or shopping for the next one.
The part I’m still refining
I’m not holding this up as finished. A month of real use has shown me where it’s weak.
The Apple Watch capture isn’t consistent enough yet; it still requires me to look at the screen and confirm things processed correctly, which defeats the hands-free promise. So one of the things I want to build is a validation layer: when an audio file comes in, the system checks whether it was actually processed, and flags it if something went wrong so I can see why. That’s the kind of refinement that only surfaces after you’ve lived with something. It’s not a new build. It’s tending the thing I have.
When a truly hands-free device exists, something even more frictionless than the watch, I can see voice capture becoming my default. Until then, I’m honest about how I actually use it.
On the security question
A couple of people raised a fair concern: if someone hacked my Supabase account, they’d have all my data.
I take that seriously, and I won’t pretend the setup is invulnerable. But here’s how I actually weigh the risk. Pulling that off would require someone targeting me specifically, knowing exactly what to look for, where it lives, and very likely social-engineering me successfully to get there. I’m one individual. The big, trusted tools that hold millions of people’s data are the ones getting breached on a regular basis, precisely because they’re worth the effort. A single person’s self-hosted system is a far less attractive target.
There’s also a simpler truth underneath it: there’s nothing in here I’d be devastated to have exposed. It’s tasks, projects, client work, notes, and book highlights; I don’t have secrets. If all of it went public tomorrow, it would be inconvenient, but it wouldn’t ruin me. That changes the math. The data worth guarding at all costs is the data that can hurt you if it leaks, and I’ve been intentional about not putting that kind of thing in here. For where I am right now, I’m comfortable with the tradeoff, and I’ll keep reassessing it as the system holds more.
The thing I actually want to model
The barrier to building has collapsed. You can make almost anything now, cheaply, in a couple of days. That’s genuinely exciting. It’s also the trap, because when building is this easy, the temptation is to keep building, to chase the next shiny system every time the current one loses its shine.
I don’t want to be that. I want to be someone who builds a real solution and then lives in it; refining it, growing with it, letting it evolve instead of replacing it. The discipline these days isn’t building. Building is the cheap part. The discipline is staying.
That’s what I’m trying to do here. And it’s what I’ll keep showing you, not the next build, but what it actually looks like to keep using the thing you made.
A part-two video is coming soon with more of what’s changed since the original. If running your own system on a couple of dollars a month sounds appealing, or if you’ve been the person jumping from tool to tool and you’re tired of it, comment and tell me where you are with it. I read every one.